An Introduction to Natural Language Programming

By Raghuram Srinivas, DataScience@SMU Student
The natural language programing paradigm builds on the premise of getting machines to read and understand natural human language, like English. These form the basis for the advanced form of computing called cognitive computing. Cognitive systems are redefining the nature of the relationship between people and machines. They are fast pervading the IT landscape across many industries and are able to play the role of assistant or coach for the user. In many cases they may act independently solving real problems and answering real questions. A foundational capability of such systems is their ability to understand the user’s natural language.
The field of data sciences forms an underlying requirement for building such systems. I present a two-part blog series that gives an introduction into this capability. We will walk through a simple example of analyzing the sentiments of movie reviews and building a machine learning model that can classify a review as either a positive or a negative review. Part one describes the problem and provides a design approach. Part two gets into the mechanics of implementing the design using python programming language.
The Data
We will use a movie review data set provided with the python’s natural language toolkit package(NLTK) for our use case. The NLTK package provides a collection of functions and resources that enable working with human language data. (More information can be found at nltk.org)
This data set consists of 2,000 reviews of Hollywood movies classified as either positive or negative. Provided below are a couple of examples; one text is a positive review of a movie and the other is a negative review of a movie.

Our goal is to come up with a machine learning model that is able to learn from these reviews, understand how to interpret a block of English text, and understand what makes a positive or a negative review. Once built the model can be used to classify any new reviews as either positive or negative reviews automatically.
The Design Approach
The first step in solving a problem involves identifying a good design approach for building a model. Most machine learning algorithms need the data to be in a tabular form with each row representing the movie review and each column representing an attribute of the review text. This is typically called a feature vector and this forms a numerical representation of the text in a tabular form. The features are the attributes derived for each movie review and these in turn help predict the response: a positive or negative review. The model is only as good as the data it is trained on. Hence the step of creating the most optimal feature vector assumes a lot of importance in determining the end result.
There are multiple features that can be derived from the reviews. The following are some examples:
- The size of each review could be a feature, maybe there is a pattern where positive reviews are longer than the negative ones.
- The frequency of occurrences of the most common words or emoticons in each review may have a pattern to a review being positive or negative.
- The frequency of occurrences of the adjectives in each review may indicate a pattern. This is quite plausible as people tend to use words like “good” and “nice” when describing things they like versus words like “bad” and “horrible” for the contrary.
We will use the approach of counting adjectives in each review for our purposes.
The Feature Vector
As described in the previous section, we will derive a feature vector where each feature represents an adjective and the rows represent the movie reviews. The end result of this exercise would yield a vector similar to one below.
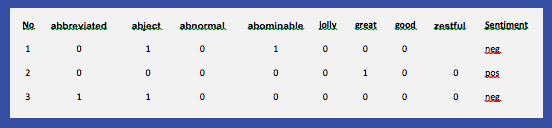
Here each column (except sentiment) represents the adjectives that appear at least once across all reviews and each row represents each movie review with a 0 or 1 indicating if the adjective appeared in it. The column “sentiment” is the “response variable” or the field we want our model to predict.
In our example above, the first review is a negative review. The review contains words such as abject, abominable and zero. The second review is a positive review and it contains adjectives such as great and youthful. Next this can be built out for all the rest of the reviews in the dataset and then the vector can be fed into the machine learning algorithms to create a model, which can then predict if any new movie review is a positive review or a negative review.
Conclusion and Next Steps
This post provides an overview of the problem statement and the design approach. Part two of this blog will focus on data analytics where we will get into the mechanics of achieving the outlined design using python programming language and the relevant packages to assemble data and build machine learning algorithms.
Learn more about the Master of Science in Data Science delivered online at SMU.
Last updated May 2016